S3
Stores data as objects with metadata, accessible via an API.
Key Features
- Object storage
- limitless storage
- No limit on the number of files you can have
- Files can be uploaded/deleted/read with the console, CLI, APK, SDK, etc
- Unlike EBS or EFS, it doesn’t have to be attached to a service first
- Can be used by any workload, including serverless applications, data lakes, and backups
- automatic scaling and low cost
- bucket storage size grows automatically as you add more objects into it, and there is virtually no limit on the bucket total storage capacity
- No file system
- Even though you’re not managing a file system, there is organization
- you can and must create buckets
- Storage classes
- Resources
Advanced Features
- diagram
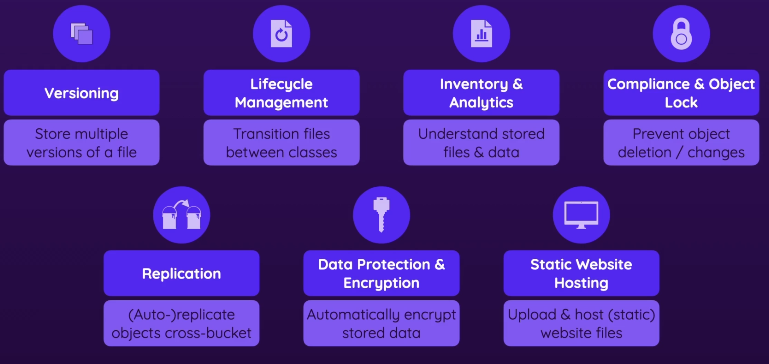
- Version
- when you update a file, the new version is stored and the older version is not deleted
- This option costs extra money
- Lifecycle management
- What if you have certain files that are accessed frequently first month but accessed less later?
- You can set certain rules which AWS will automatically transition files between classes
- Inventory & Analytics
- Sometimes you wanna get an overview/summary
- Various features on top of S3 (advanced) that gives you more insights in your bucket
- Compliance & object lock
- Achieving compliance if required in your company
- Telling certain files shouldn’t be deletable
- Replication
- Cross bucket replication - you can set certain rules to AWS to copy different files to different buckets automatically
- Backup files — make sure your data is saved in case a bucket /file gets deleted/compromised
- Available in a single region (between buckets in same region), or cross-region (outside of current region)
- Data Protection & Encryption
- File level or bucket level encryption
- Your files can be encrypted automatically when you upload them & decrypted automatically when you’re accessing them
- Static website hosting
- You can put website files in there if it doesn’t have server-side code
- consists of only HTML, CSS, and JS
- Properties > enable Static Website hosting
- You can use a custom domain instead of the AWS generated one
Buckets
- diagram

- “folders”
- nested buckets are NOT allowed
- Scalibility
- You can create multiple sibling buckets, and every bucket can store infinite number of files
- No need to choose a bucket size in advance
- Buckets are regional
- You can distribute multiple buckets across multiple regions
- Unique name
- Must have a unique name
- For ALL AWS BUCKETS in the ENTIRE WORLD
- Flat structure
- Has no directories
- Can assign prefixes to your files (so you can create very long file names), then you can organize your files by prefix
- Detailed permissions system
- You can control a bucket/file level access, who has access to which
- bucket policies or access control lists (more detailed but X recommended)
- S3 Block Public Access
- It can forcibly block new or existing public ACL/policy changes at the bucket or account level
- During configuration
- You can make your bucket public, but by default it’s set as private
- You need to make extra configurations after you uncheck that
- Bucket policy → (read more) → you can see different examples (ex. granting read-only permission to an anonymous user)
- When you upload a file, go through the settings first (scroll down) and upload
- you can choose a Storage Class
- You can make your bucket public, but by default it’s set as private
Bucket policies
- Bucket policies are IAM policies that define permissions, but NOT attached to users or roles, but to buckets
- They control who/what is allowed to certain buckets, and which kinds of actions are allowed on a given bucket
Storage Class
- diagram
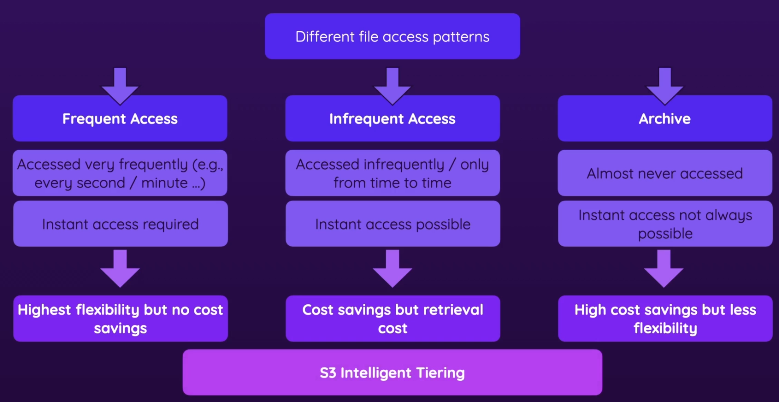
- Key feature of S3, a feature that can help you save money
- Different storage classes for different file access patterns
- Frequently
- Person/application needs access very frequently (every min/sec)
- Instant access to frequently used data
- Highest flexibility with no/little cost savings
- Standard, Reduced redundancy
- Infrequent Access
- time to time (ex. once a month)
- You still want instant access → retrieval cost
- cost savings → if you don’t access your files, you’re paying less for storing them
- One Zone-IA
- Archive - Glacier
- access almost never again or very rare access
- Maybe you just have to store it for legal reasons
- Instant access not always possible (some needs waiting for couple hours)
- High cost savings but less flexibility
- Glacier series
- Frequently
- S3 Intelligent Tiering
- AWS analyzes the access patterns and automatically move it to a fitting category
- you save less than doing manually but better than doing nothing
Glacier classes
- Main classes
- S3 Glacier Instant Retrieval
- data must be stored long-term and access is highly unlikely but instant access is needed, if data must be accessed
- S3 Glacier Flexible Retrieval (formerly just “S3 Glacier”)
- Amazon S3 Glacier Deep Archive
- S3 Glacier Instant Retrieval
- “Glacier” is sometimes referenced as a standalone service, but it’s always referred to the S3 Glaciers
- it’s always these three storage classes which are optimized for long-term file storage with low-frequency file access patterns