After a model is developed, it needs to be made accessible to users.
Challenges
- Concept drift and data drift
- Concept drift: When y given x changes
- Data drift: When x changes
- What if your data changed after system is deployed?
- changes in the data patterns and relationships that the ML model has learned, potentially causing a decline in the production model quality
- retrain ML models using new data
- Ex (speech recognition): People started using a new model of smartphone, which has a different microphone, so the audio sounds different. Then the performance of the speech recognition system degraded
- You need to recognize how the data has changed and if you need to upgrade your learning algorithm as a result
- Data can change gradually/suddenly
- Make sure you can detect and manage any changes!!
- Software engineering issues
There are lots of design choices for mapping input
xto outputy- Checklist questions
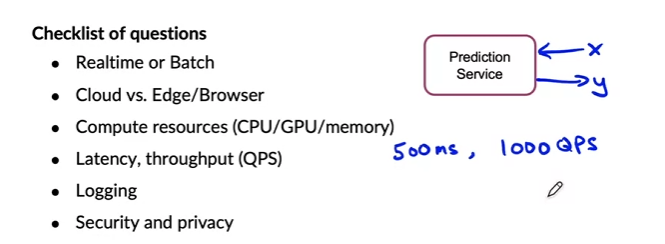
- Log as much as possible
- Checklist questions
Deployment patterns
- First deployment and maintaining deployment is different
Common deployment cases
- New product/capability
- Automate/assist with manual task
- Replace with previous ML system Key ideas
- Gradual ramp up with monitoring
- Rather than sending lots of traffic to a not proven learning algorithm, you many only send a small amount of traffic and monitor it
- Rollback
- If something’s not working, you can revert to the earlier system
Deployment patterns
- Shadow mode
- The ML algorithm “shadow” the human inspector and run in parallel with them
- Lets it verify the performance of the ML models before letting it make any real decisions
- Canary deployment
- monitor system and ramp up traffic gradually
- Ex) Monitor that 1% of users’ reaction, and either gradually ramp up (if it’s going well) or rollback (if not)
- Blue green deployment
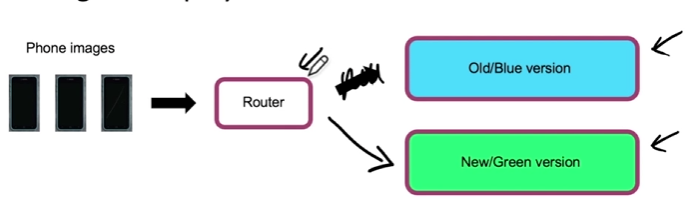
- just switch the router
- easy way to enable rollback
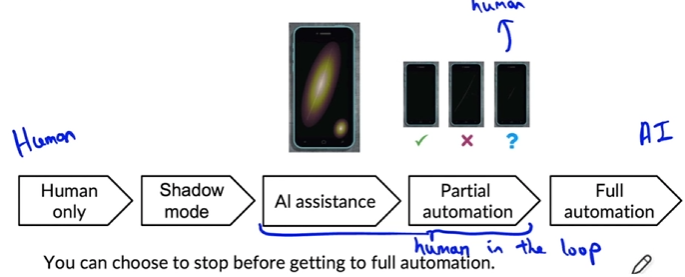
Degrees of automation
- Deployment is not 0 or 1, it’s a scale
Monitoring & Maintaining
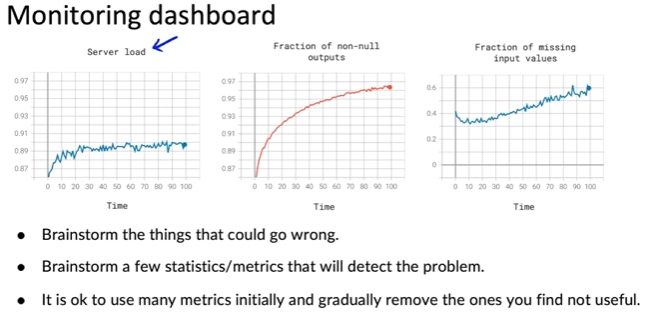
- Common practice is to set threshold for alarms
- Adapt metrics and thresholds over time to make sure they’re useful for you
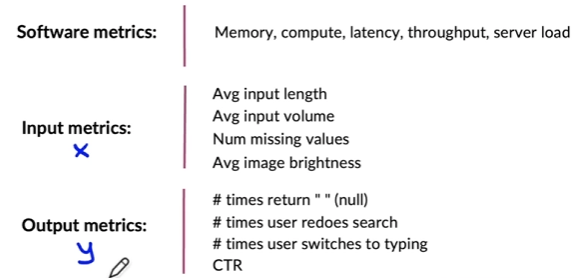
Examples of metrics to track
Model maintenance
- Just like software
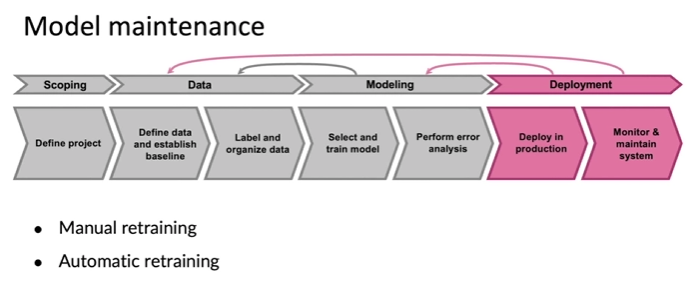
- Manual retraining is far more common than automatic retraining
Pipeline monitoring
Many AI systems are not just a single machine learning model running a prediction service, but instead involves a pipeline of multiple steps.
- Speech recognition example
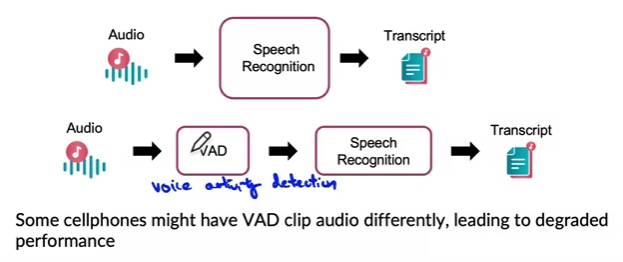
- VAD (voice activity detection): Detects if someone is talking
- Speech recognition: Learns to transcribe text
- It’s useful to brainstorm metrics to monitor that can detect changes including concept drift or data driven or both, and multiple stages of the pipeline
- Also monitor the rate at which the data changes
- user data usually have slower drift
- Enterprise data (B2B) can shift quite quickly