Tagging and Extraction
- Tagging
- Allows us to extract structured data from unstructured text
- Instead of asking the LLM to write a conversational paragraph, you pass in an unstructured piece of text along with a structured description. You then use the LLM to evaluate the text and generate a response strictly in the format of that description.
- diagram
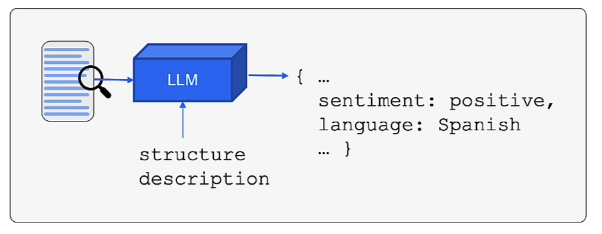
- Extraction
- the process of pulling out specific pieces of information (entities) from a body of text, rather than just categorizing the text as a whole
- we can extract specific entities from the text as a list, also represented by structured description
- diagram
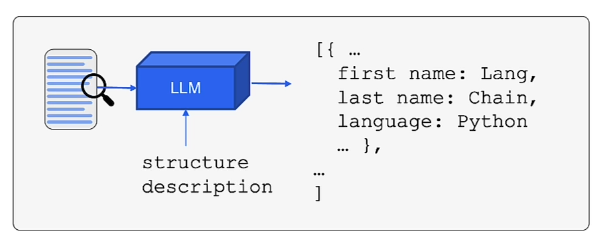
- the process of pulling out specific pieces of information (entities) from a body of text, rather than just categorizing the text as a whole
- Tagging VS Extraction
- They both use structured output/function calling
- Tagging (Classification): Applies labels to the entire text.
- Input: “The new iPhone battery dies so fast, I hate it.”
- Output:
{"sentiment": "negative", "topic": "technology"}
- Extraction: Pulls out individual entities or data points mentioned within the text.
- Input: “John Doe bought 30 shares of Apple on February 19th for $150 each.”
- Output:
{"name": "John Doe", "asset": "Apple", "quantity": 30, "price": 150, "date": "February 19th"}
Tagging (w/ OpenAI functions)
from typing import List
from pydantic import BaseModel, Field
from langchain.utils.openai_functions import convert_pydantic_to_openai_function
class Tagging(BaseModel):
"""Tag the piece of text with particular info."""
sentiment: str = Field(description="sentiment of text, should be `pos`, `neg`, or `neutral`")
language: str = Field(description="language of text (should be ISO 639-1 code)")class Tagging→pydantic model- list of attributes we want to “tag” the text with, which is
sentimentandlanguage
- list of attributes we want to “tag” the text with, which is
- this is how it looks like when we convert it to function:
convert_pydantic_to_openai_function(Tagging){'name': 'Tagging',
'description': 'Tag the piece of text with particular info.',
'parameters': {'title': 'Tagging',
'description': 'Tag the piece of text with particular info.',
'type': 'object',
'properties': {'sentiment': {'title': 'Sentiment',
'description': 'sentiment of text, should be `pos`, `neg`, or `neutral`',
'type': 'string'},
'language': {'title': 'Language',
'description': 'language of text (should be ISO 639-1 code)',
'type': 'string'}},
'required': ['sentiment', 'language']}}
- actually using the pydantic class → openai function
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
# simple model, we wnat it to be deterministic
model = ChatOpenAI(temperature=0)
# also repeated just a while ago
tagging_functions = [convert_pydantic_to_openai_function(Tagging)]
prompt = ChatPromptTemplate.from_messages([
("system", "Think carefully, and then tag the text as instructed"),
("user", "{input}")
])
# bind the model to the tagging functions (rn we're forcing to always use the tagging function)
model_with_functions = model.bind(
functions=tagging_functions,
function_call={"name":"Tagging"}
)
tagging_chain = prompt | model_with_functions
tagging_chain.invoke({"input": "I love langchain"})AIMessage(content='', additional_kwargs={'function_call': {'name': 'Tagging', 'arguments': '{"sentiment":"pos","language":"en"}'}})
- the output is still nested. we can use an output parser that takes this AI message & parses out the JSON (becoz thats what we need)
- we use
JsonOutputFunctionsParser()
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
tagging_chain = prompt | model_with_functions | JsonOutputFunctionsParser()
tagging_chain.invoke({"input": "non mi piace questo cibo"})
# {'sentiment': 'neg', 'language': 'it'}Extraction (w/ OpenAI functions)
- let’s say we want to extract a list of
Personobj
from typing import List
from pydantic import BaseModel, Field
from langchain.utils.openai_functions import convert_pydantic_to_openai_function
from typing import Optional
class Person(BaseModel):
"""Information about a person."""
name: str = Field(description="person's name")
age: Optional[int] = Field(description="person's age")
class Information(BaseModel):
"""Information to extract."""
people: List[Person] = Field(description="List of info about people")
convert_pydantic_to_openai_function(Information)- this is how the
Informationlooks like after being converted toopenai_function
{'name': 'Information',
'description': 'Information to extract.',
'parameters': {'title': 'Information',
'description': 'Information to extract.',
'type': 'object',
'properties': {'people': {'title': 'People',
'description': 'List of info about people',
'type': 'array',
'items': {'title': 'Person',
'description': 'Information about a person.',
'type': 'object',
'properties': {'name': {'title': 'Name',
'description': "person's name",
'type': 'string'},
'age': {'title': 'Age',
'description': "person's age",
'type': 'integer'}},
'required': ['name']}}},
'required': ['people']}}
- actually using the converted
Informationtoopenai_function
extraction_model = model.bind(
functions=[convert_pydantic_to_openai_function(Information)],
function_call={"name": "Information"}
)
extraction_model.invoke("Joe is 30, his mom is Martha")
# AIMessage(content='', additional_kwargs={'function_call': {'name': 'Information', 'arguments': '{"people":[{"name":"Joe","age":30},{"name":"Martha"}]}'}})
# it correctly gives the arguments to BaseModel!!!prompt = ChatPromptTemplate.from_messages([
("system", "Extract the relevant information, if not explicitly provided do not guess. Extract partial info"),
("human", "{input}")
])
chain = prompt | extraction_model
chain.invoke({"input": "Joe is 30, his mom is Martha"})
# AIMessage(content='', additional_kwargs={'function_call': {'name': 'Information', 'arguments': '{"people":[{"name":"Joe","age":30},{"name":"Martha"}]}'}})
# gives same results- with LCEL (LangChain Expression Language) +
JsonKeyOutputFunctionsParser- use
key_name→ extract specific fields - u can use
JsonOutputFunctionsParserbut this won’t allow getting the specific keys
- use
chain = prompt | extraction_model | JsonKeyOutputFunctionsParser(key_name="people")
chain.invoke({"input": "Joe is 30, his mom is Martha"})
# [{'name': 'Joe', 'age': 30}, {'name': 'Martha'}]Tagging/Extraction w/ a real web article
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
documents = loader.load()
doc = documents[0] # there is only 1 element in documents (the text from website)
# get first 10,000 characters of the text
page_content = doc.page_content[:10000]Tagging
from typing import List
from pydantic import BaseModel, Field
from langchain.utils.openai_functions import convert_pydantic_to_openai_function
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
class Overview(BaseModel):
"""Overview of section of text."""
summary: str = Field(description="Provide a concise summary of the content.")
language: str = Field(description="Provide the language that the content is written in.")
keywords: str = Field(description="Provide keywords related to the content.")
model = ChatOpenAI(temperature=0)
tagging_fns = [
convert_pydantic_to_openai_function(Overview)
]
tagging_model = model.bind(
functions=tagging_fns,
function_call={"name":"Overview"}
)
tagging_chain = prompt | tagging_model | JsonOutputFunctionsParser()
tagging_chain.invoke({"input": page_content}){'summary': 'The article discusses building autonomous agents powered by LLM (large language model) as the core controller. It covers components such as planning, memory, and tool use, along with examples and challenges in implementing LLM-powered agents.',
'language': 'English',
'keywords': 'LLM, autonomous agents, planning, memory, tool use, proof-of-concepts, challenges'}
Extraction
- setting function schemas
class Paper(BaseModel):
"""Information about papers mentioned."""
title: str
author: Optional[str]
class Info(BaseModel):
"""Information to extract"""
papers: List[Paper]- setting up extraction chain
paper_extraction_function = [
convert_pydantic_to_openai_function(Info)
]
extraction_model = model.bind(
functions=paper_extraction_function,
function_call={"name":"Info"}
)
template = """A article will be passed to you. Extract from it all papers that are mentioned by this article follow by its author.
Do not extract the name of the article itself. If no papers are mentioned that's fine - you don't need to extract any! Just return an empty list.
Do not make up or guess ANY extra information. Only extract what exactly is in the text."""
prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", "{input}")
])
extraction_chain = prompt | extraction_model | JsonKeyOutputFunctionsParser(key_name="papers")
extraction_chain.invoke({"input": page_content})[{'title': 'Chain of thought (CoT; Wei et al. 2022)',
'author': 'Wei et al. 2022'},
{'title': 'Tree of Thoughts (Yao et al. 2023)', 'author': 'Yao et al. 2023'},
{'title': 'LLM+P (Liu et al. 2023)', 'author': 'Liu et al. 2023'},
{'title': 'ReAct (Yao et al. 2023)', 'author': 'Yao et al. 2023'},
{'title': 'Reflexion (Shinn & Labash 2023)', 'author': 'Shinn & Labash 2023'},
{'title': 'Chain of Hindsight (CoH; Liu et al. 2023)',
'author': 'Liu et al. 2023'},
{'title': 'Algorithm Distillation (AD; Laskin et al. 2023)',
'author': 'Laskin et al. 2023'}]
what if we want to do the whole article??
- we do text splitting
- the plan:
- we take in the page content, split it up into
splits, pass those individual splits to the extraction chain, join all the results!
- we take in the page content, split it up into
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_overlap=0)
# testing
splits = text_splitter.split_text(doc.page_content)
len(splits) # 15-
each
splitis a chunk of the web article -
we will need a function that flattens lists
- we need this because we want to extract list of mentioned papers per
splitand merge them all together!
- we need this because we want to extract list of mentioned papers per
def flatten(matrix):
flat_list = []
for row in matrix:
flat_list += row
return flat_list
flatten([[1, 2], [3, 4]]) # [1, 2, 3, 4]from langchain.schema.runnable import RunnableLambda
prep = RunnableLambda(
lambda x: [{"input": doc} for doc in text_splitter.split_text(x)]
)
# [
# {"input": "Chunk 1 text"},
# {"input": "Chunk 2 text"}
# ]
chain = prep | extraction_chain.map() | flatten
chain.invoke(doc.page_content)RunnableLambda- a simple wrapper that takes in a function and converts it into a runnable object
- converts list of text into list of dictionaries where text is the input key
chain = prep | extraction_chain.map() | flatten- we pass in list of dictionaries to
extraction_chain.map() map()tells langchain to take the list and run the extraction chain on every single item independently and in parallel- it returns the results in a list matching the input list → a matrix (list of lists)
- so we
flattenit in the end
- we pass in list of dictionaries to