- Tech Stack
- ChromaDB for vector storage
- Streamlit to abstract a lot of UI application
- Google Gemini and GCP for Vertex AI to embed documents and perform queries
- Langchain to put all frameworks together
- Setup
- Create new project and service account
- Set environment variable
export GOOGLE_APPLICATION_CREDENTIALS = $PATH TO KEY
- Add environment variable to Shell configuration
- Task 3 (Previous tasks are just setup)
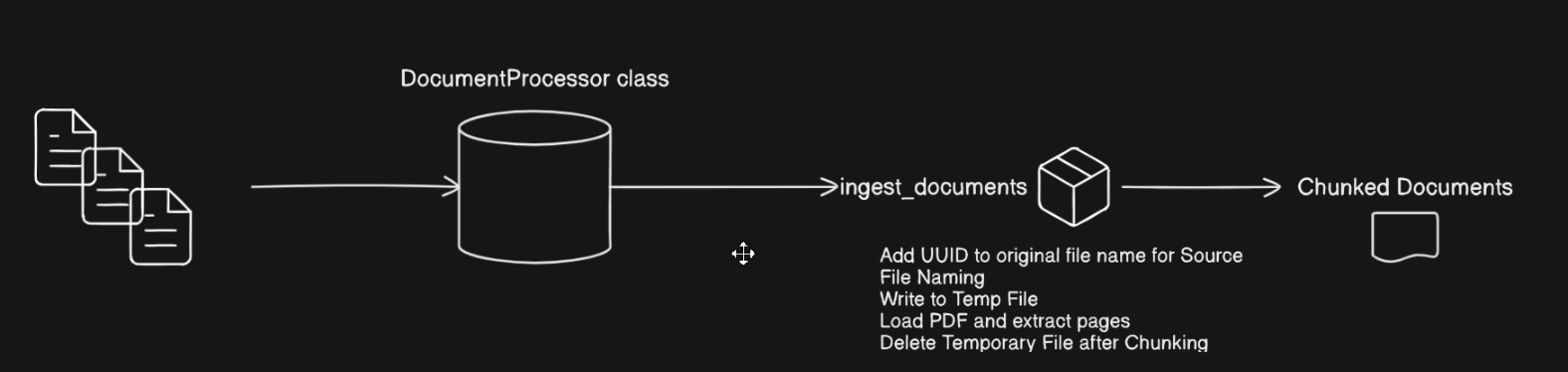
- We build the document processor class that we will be using for out data ingestion pipeline
- The documents, or PDFs (1) → loaded into DocumentProcessor class →
ingest documents (algorithm: creates a temp file and use it for the name of the individual chunks that we’re taking from each document, then delete it) → return the chunked documents
- Task 4
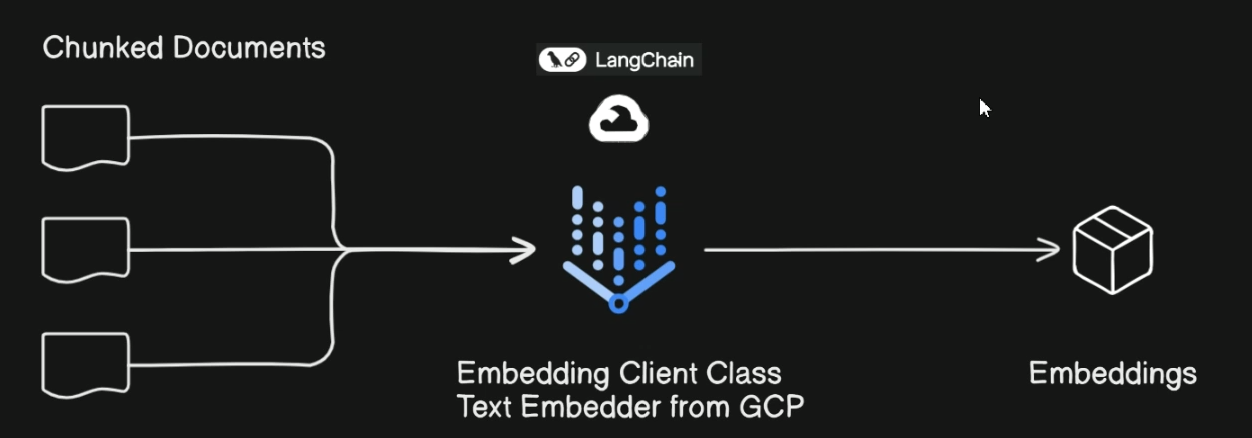
- Task 5-6
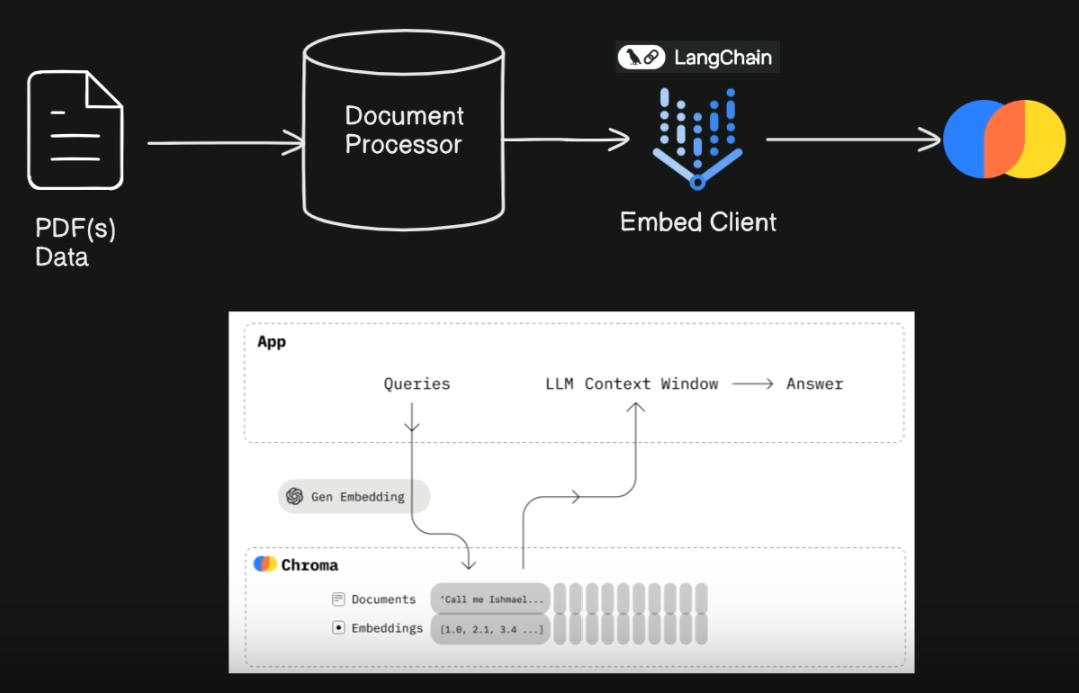
- We index and store all vectors(Embeddings) and their metadata in ChromaDB database, where we can query and ask questions
- Then, a single Chroma collection that will contain the text chunks obtained from splitting the processed documents.
- Task 7-8
- Created the
QuizGenerator class that takes a topic, # of questions, and a vectorstore for querying related information
init_llm: initializes and configues the LLM for generating quiz questionsgenerate_question_with_vectorstore: generates a quiz question based on topic proided using a vectorstoregenerate_quiz: Generate a list of unique quiz questions based on the specified topic and number of questionsvalidate_question: checks if question is unique
- Used Pydantic to create
QuestionSchema and Choice model
- Used LangChain Expression Language (LCEL)
- Task 9
- Created the
QuizManager class: We initialize it with a list of quiz question objects. Each quiz question object is a dictionary that includes the question text, multiple choice options, the correct answer, and an explanation. The initialization process should prepare the class for managing these quiz questions, including tracking the total number of questions.
- init()
- get_question_at_index(): to know which question we’re currently on, to ensure that the question is within bounds
- next_question_index():
- What ppl wrote in their resume lol
Developed a backend module for generating exam questions from provided PDF files. It was developed in Python, using the VertexAI API LLM and orchestrated by LangChain. Also, PyPDF was used for optimal batch handling, as well as ChromaDB as a vector database for embeddings storage with VertexAIEmbeddings and RAG development. To test what was implemented, an agile UI was integrated using Streamlit, as well as LangSmith dynamic management for request monitoring and Pydantic for schema development.