
- Different goals/requirements
- In research, the team is set to achieve one specific goal (usually to beat the state of the art benchmark)
- In production, different teams have often different goals
- MLEs may want to develop a model that recommends an item the user would want to click, but the Sales team may want a model that recommends the most expensive item that can generate most sales
- It’s important to understand ALL takes
- For example, in research, ensembling is used in many research projects, but they’re often too complex to be useful in production
Computational Priorities
Research prioritizes high Throughput, production prioritizes low Latency.
- When processing queries one at a time, higher latency means lower throughput. When processing queries in batches, however, higher latency might also mean higher throughput.
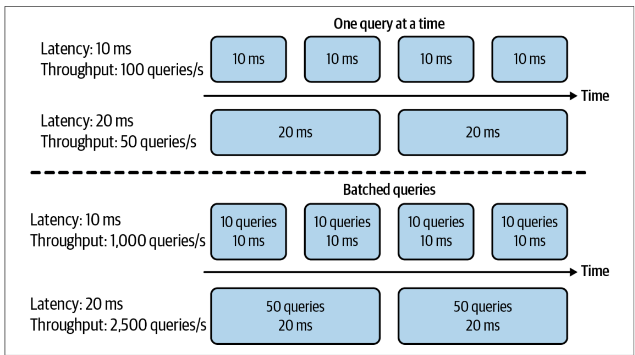
- (To read this part of the book again)
Data
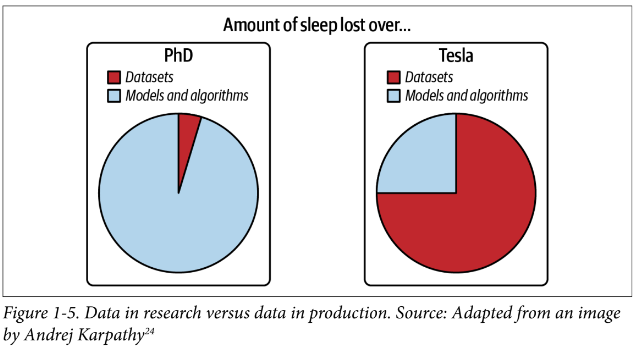
- Research
- Dataset is usually historical (already exists), often clean and well-formatted, allowing you to docus on model development / architectures
- Production
- Data is usually VERY messy, unstructured: Incorrect labels (maybe you need to relable everything), bias (you might not even know if there is a bias), the data might be sparse, imbalanced, or incorrect
- Working with data constantly generated by users, systems, 3rd party data
- Privacy and regulatory issues
Fairness
- Researchers during research phase:
- “Let’s try to get state of the art first and worry about fairness when we get to production.” (lol) → Often it’s too late
- When ML algorithms are deployed at scale, they can discriminate against people at scale. If a human operator might only make sweeping judgments about a few individuals at a time, an ML algorithm can make sweeping judgments about millions in split seconds.
Interpretability
- Since most ML research is still evaluated on a single objective, model performance, researchers aren’t incentivized to work on model interpretability. However, interpretability isn’t just optional for most ML use cases in the industry, but a requirement.
- Reasons
- Users (leaders and end users) can understand why a decision is made so that they can trust a model and detect potential
- Developers can debug and improve the model.
Job search
- Companies can’t risk ML research because it takes tens of millions of dollars to compute + massive amount of data
- The vast majority of ML-related jobs will be, and already are, in productionizing ML.