- Computerphile - https://youtu.be/gY4Z-9QlZ64?si=5Ao4JsDppzZH_Fnd
The current situation (feb 2025)
- tech companies have been competing of building the biggest, most performant model by just making everything bigger (more dataset, making model bigger), training them until they are better
- the idea is that if you have 1000s of GPUs & billions of money, you’re in an advantage because you have that power to train the largest models
- most companies (like OpenAI) keep everything secret
- just expose it thru web interfaces
- dont tell how they trained it, params, the dataset, etc
- but meta has a much more open policy
- the models are out of reach for most people - they can run/refine them, but cannot train them from scratch (no resource/money)
- Suddenly, small company in China released a model DeepSeek
- you can train with more limited hardware and money
- you can train the most recent variant of models MUCH more efficiently in terms of the amount of data you need to collect (which was pain)
- gamechanger!
DeepSeek R1
-
V3
- their flagship model (another large transformer)
- lots of more performance benefits
-
MoE
- diagram
- diff bits of network focused on different tasks
- early stages will “root” to different parts of the network and only activate only a small part of it (lets say 30B params, which is a HUGE saving)
- MUUUUCH more efficient
- pre-existing: 1 chatbot to rule all fields (master of none kind of situation)
- training takes lots of energy (expensive)
- inference also super expensive → if you have a model with 4-5B params, you have to store them somewhere. And when you run through it, that ALL gets activated and you have to work math through the WHOLE MODEL to get the prediction
- since this tells you what the next word is and goes back then the next word…its too expensive
- diagram
-
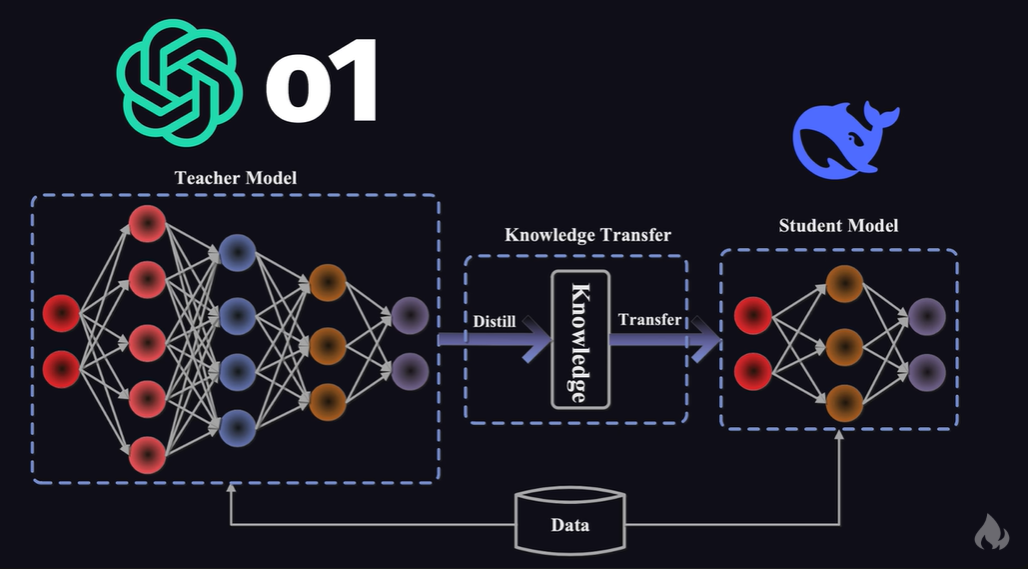
Distillation
- taking your huge model (ex. 670B), ask it a bunch of questions in a certain field, and use the answers to train a smaller model (ex. 8B) to do the exact thing (often it will work)
- certainly decent performance
- why use 670B params and all these gpus when u can get a 8B model and run it on your 4090?
-
R1
- latest model
- chain of thought
- useful for problem solving
- adds computational cost during inference but performance goes up
- OpenAI pioneered this but they don’t tell you how to do it
- fully public (OpenAI’s methos are closed)
- trained this with much more limited data
- create a dataset (question - correct CoT - correct answer)
- R1 actually trained it with ONLY THE ANSWERS
- requires much less data
- (reinforcement learning) give it lots of math questions, reward it if its right, reward if it wrote some kind of internal monologue in correct format
- over time it trains, and monologue gets better and better
- and in the end it has a chat with itself and solves the problem
-
fireship
- https://youtu.be/hpwoGjpYygI?si=rhaTik1gJHjIlEp3
- basically distillation