- ComfyUI 설치
- ComfyUIManager 설치
- 7zip 사용해서 extract하기
README_VERY_IMPORTANT.txt읽기ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUIextra_model_paths.yaml.example에서 example 지우기- vscode로 열어서 base path 바꾸기
base_path: C:\Users\artygen\Desktop\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI
기본 Workflow
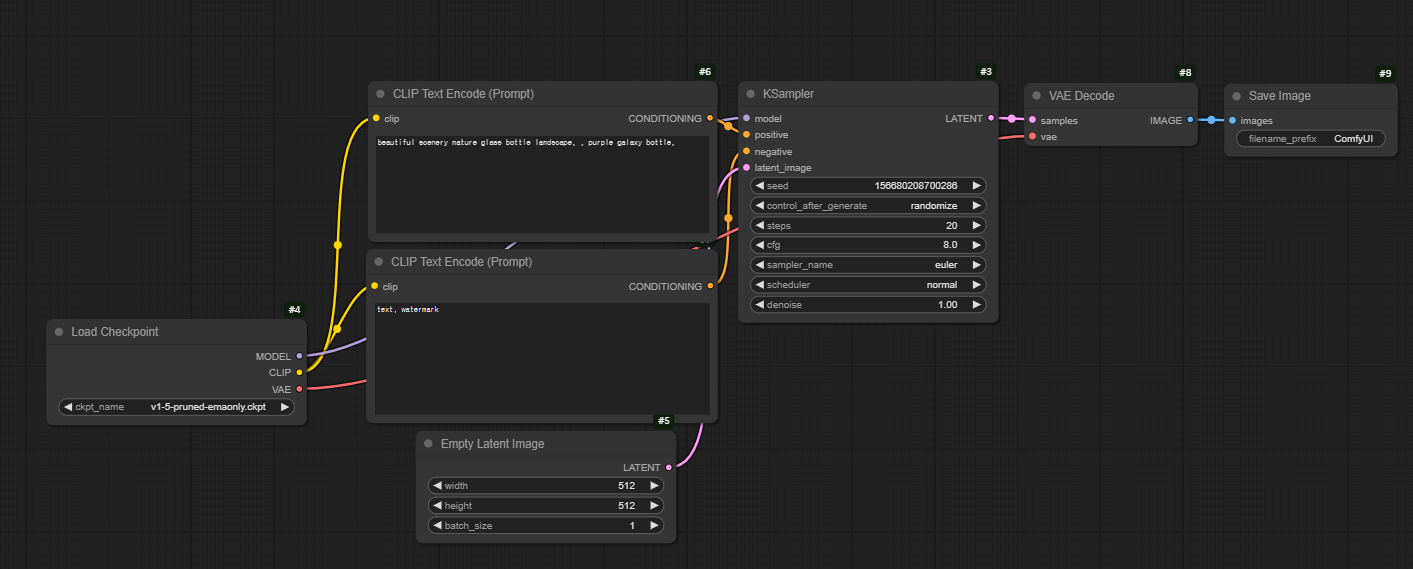
- Increasing batch size gives more output pictures
Core Process
CLIP Text Encode node: Process your text promptEmpty Latent Image node: Starts with random noise in “latent space” (think of this as a compressed, abstract version of an image)KSampler node: Gradually denoises this random noise, guided by the prompt, until it forms a coherent imageVAE Decode node: converts the final latent image to pixels
Nodes
- Load Checkpoint
- 시작하는 node
- If you click on it you can see what checkpoints you have
- Nodes
- change colors/names
- right click > Properties Panel
- Empty Latent Image
- Latent Image: intermediate representation used by Stable Diffusion
- Pixel Image: the image output
batch_size: num of final output images- 이 노드를 빼고 이미지를 넣으면 img2img
- Add Node > image > Load image
- 이 pixel image를 latent image로 바꿔주기
- Latent Image: intermediate representation used by Stable Diffusion
- General process of images
- Random noise/empty latent space
- Latent image (transformed through the diffusion process)
- Final pixel image (decoded from latent space)
- KSampler
control_after_generate: 시드값 조정 가능denoise: 결과 이미지에 얼마나 많은 변화를 줄건가 (img2img)
Using LoRas
- think of LoRas as specialized “add-ons” that can enhance your generations in specific ways
- Purpose
- Add specific art styles (like anime, watercolor, etc.)
- Add specific characters or people
- Add specific objects or concepts
- Modify the model’s style in particular ways (like making things more detailed or cartoonish)
- Basic example
Load Checkpoint (base model) → Load LoRA → CLIP Text Encode → KSampler → VAE Decode
- Can be chained together
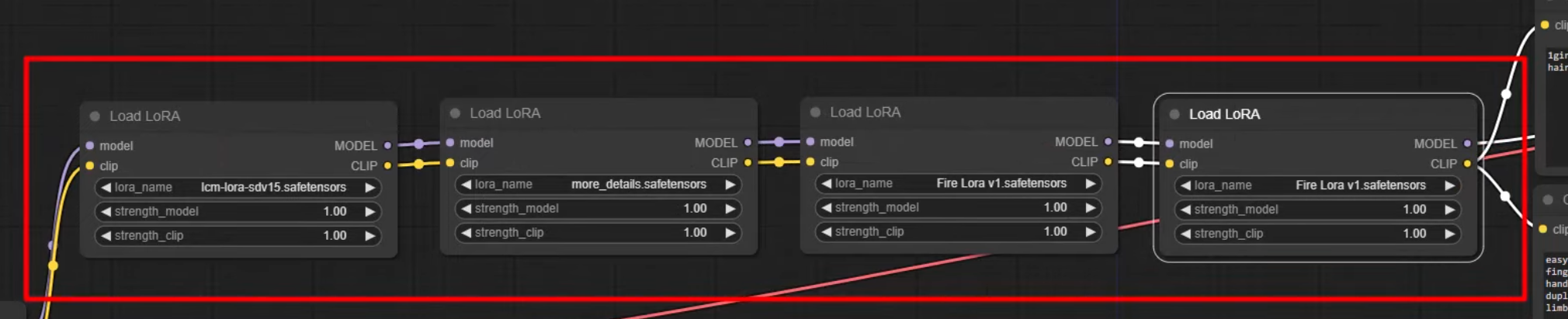
strength_model- affects how strongly LoRa affects the actual generated image
strength_clip- affects how strongly LoRa influences the prompt
- modifies the CLIP part of Stable Diffusion, which is responsible for understanding text prompts
Improving quality
- Pixel Image
- Use
UpscaleImageUsingModelNode- Put it between VAE decode and Save image
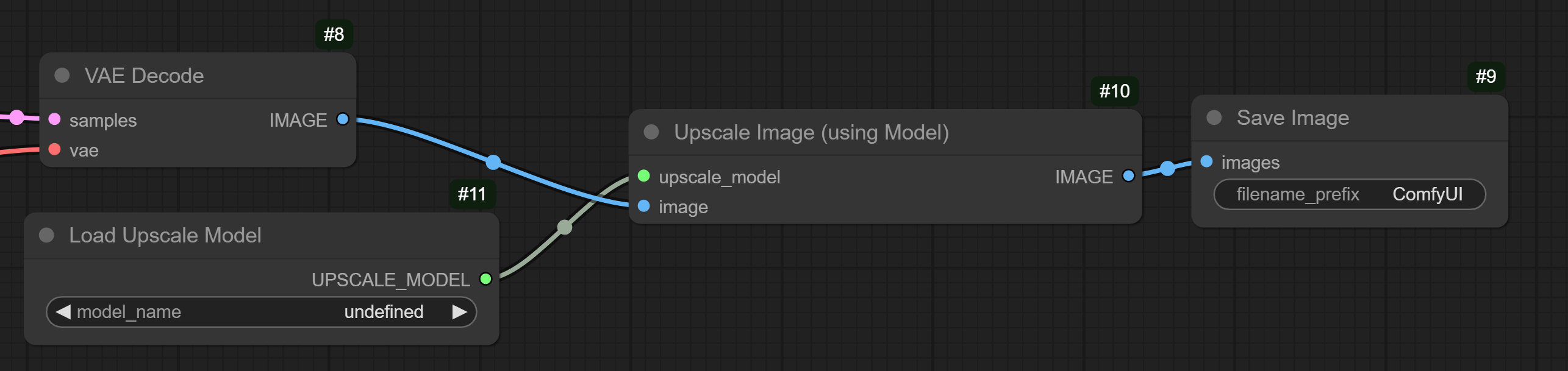
- Put it between VAE decode and Save image
- Use
LoadUpscaleModelNode
- Use
- Latent Image
- https://youtu.be/QFeUSU02gho?si=mLMaq6xPokrtbInJ
- Upscale Latent Node